Mastering Summarization Techniques: A Practical Exploration with LLM - Martin Neznal
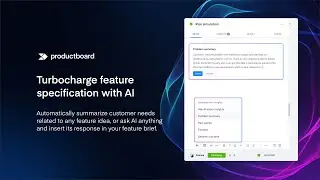
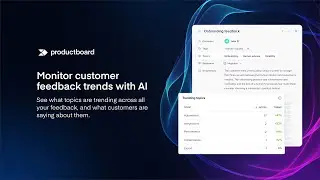
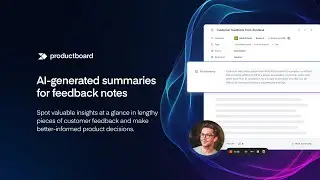
In this talk, I would like to focus on the summarization of collections of feedback and describe all its challenges. I will focus on the state-of-the-art summarization models, such as GPT-3, open source GPT variants, Bart, and other transformers as well as some extractive approaches such as Gensim. I will show how they perform for summarization of different types of text such as conversations, reviews, long & short texts, etc. 🔹 I will present what are the industry standard methods for the evaluation of summaries such as ROUGE, BLEU, BLANC, BERTscore, or Supert, and use them to evaluate the summarization models. I will show how we use these approaches in Productboard to automatically and without supervision evaluate the quality of thousands of summaries daily. 🔹 I will talk about techniques to apply to summarization models to achieve significantly better summaries such as for example fine-tuning, ways how to query GPT models, text cleaning, etc. 🔹 I will also focus on multi-document summarization and describe what are the state-of-the-art models for this task, how to evaluate the multi-document summary, and which techniques we use to preprocess the input documents when we need to summarize a collection comprising hundreds or thousands of texts into one paragraph (such as clustering, text relevancy or pre-summarization of single documents) 🔹 In the last section of my talk, I will share our experience of implementing the summarization feature in Productboard, how we incorporate the user feedback into our summarization pipeline, how we connect summaries with other ML features and also which tech stack we use, and how we scale it to deploy an independent solution for thousands of companies (each with thousands of text/feedback).